R Map:疫情这两年美国宽带覆盖有什么变化
自己编译 R 有很多好处,比如可以按需引入 OpenBLAS,用以加速一些线性代数和矩阵运算;但是,要想获得跟官方二进制包一样的开箱即用的所有能力(capabilities()),恐怕就需要耗费大量额外的精力:1、2,这个编译过程中,有很多编译环境、编译参数、依赖组件的问题需要自行解决,还不止于此,由于是自行编译的 R,那么库/包的安装也需要走源码编译,于是乎,包也有依赖问题要自行解决,尤其是遇到地理数据时,依赖很深,安装过程可能令人沮丧。
> capabilities()
jpeg png tiff tcltk X11
TRUE TRUE TRUE TRUE FALSE
aqua http/ftp sockets libxml fifo
TRUE TRUE TRUE TRUE TRUE
cledit iconv NLS Rprof profmem
TRUE TRUE TRUE TRUE TRUE
cairo ICU long.double libcurl
TRUE TRUE TRUE TRUE
R 语言相关的数据仓库 tidytuesday 第 20 周的数据是美国的宽带使用情况,具体一点,是用上了 25Mbps 及以上带宽的人口比例。分作两份数据,broadband.csv 是包含 2017 和 2019 两年且精确到县一级的数据,broadband_zip.csv 是包含 2020 且精确到邮编级别的数据。
这种情况,当然是做个地图最吸引眼球,我们来尝试一下。大体上,应该是分作两块:
- 清理数据,统一精确到县(county)级别
- 找一份新近的县级地图数据,映射我们清理好的数据
假如我们只对比 2019 和 2020 两年,对疫情前后带宽 >= 25Mbps 覆盖变化有个基本画面。那么,对于 2020 年的数据,因为它是细分到邮编街区级的,不好直接对比,我们得再找找合适的数据源,根据 zipcode 匹配出来这一级的人口数,反算实际覆盖人口,最后再聚合到县一级,重新算县一级的覆盖率,方便后续的对比绘图。不过,对于这个问题,数据提供方比较贴心的给了提示,告诉我们可以试试看 {zipcodeR} package。
再看第二块,地图数据。几个要求,覆盖新近的行政区划变更,带 fips 等 id 方便建立准确的映射关系,最好附带了合适的投影模式(比如 albers),且处理好了阿拉斯加、夏威夷的摆放。带着这些需求关键字,一番搜索,网上提到比较多的,一是 ggplot2 自带的 map_data,它的使用很简单,问题是没有 county_id,只有 county_name,而名字又常变动还有不同写法的问题,不好结合其他数据来做映射; 一是 albersusa,看着也不错,可以仓库已经是 Archived 状态;一是 usmap,试了一下,相当推荐;还有通过这条 tweet 发现的 urbnmapr,也不错,很好定制。以下简单复述一下后两个方案。
先看数据,先是 2019 年的,只需稍加处理,比如把 county_id 通过 0 补齐 5 位数字,方便后续匹配地图数据,比如 county_id == fips 之类的。
# library(tidyverse)
# library(janitor)
# library(zipcodeR)
# library(scales)
# library(usmap)
# library(sf)
# library(urbnmapr)
bu19 <- read_csv('https://raw.githubusercontent.com/rfordatascience/tidytuesday/master/data/2021/2021-05-11/broadband.csv', na = c("-", "", NA)) |>
clean_names() |>
rename(state = st) |>
mutate(county_id = sprintf("%05d", county_id))
处理之后的结果,我们这里只关注 broadband_usage,它是 2019 的统计结果。
state county_id county_name broadband_availabil… broadband_usage
<chr> <chr> <chr> <dbl> <dbl>
1 AL 01001 Autauga Cou… 0.81 0.28
2 AL 01003 Baldwin Cou… 0.88 0.3
3 AL 01005 Barbour Cou… 0.59 0.18
4 AL 01007 Bibb County 0.29 0.07
5 AL 01009 Blount Coun… 0.69 0.09
6 AL 01011 Bullock Cou… 0.06 0.05
2020 年的数据,稍微复杂一点。
bu20 <- read_csv('https://raw.githubusercontent.com/rfordatascience/tidytuesday/master/data/2021/2021-05-11/broadband_zip.csv') |>
clean_names() |>
rename(state = st) |>
mutate(postal_code = sprintf("%05d", postal_code),
county_id = sprintf("%05d", county_id)) |>
# 分割
left_join(zip_code_db |> select(zipcode, population),
by = c(postal_code = "zipcode")) |>
mutate(q = population * broadband_usage) |>
group_by(county_id) |>
summarise(usage = sum(q) / sum(population))
left_join 之前的数据长这样,注意它是到 postal code 级别的细分数据。
# A tibble: 6 x 8
state county_name county_id postal_code broadband_usage
<chr> <chr> <chr> <chr> <dbl>
1 SC Abbeville 45001 29639 0.948
2 SC Abbeville 45001 29620 0.398
3 SC Abbeville 45001 29659 0.206
4 SC Abbeville 45001 29638 0.369
5 SC Abbeville 45001 29628 0.221
6 LA Acadia Parish 22001 70516 0.032
# … with 3 more variables: error_range_mae <dbl>,
# error_range_95_percent <dbl>, msd <dbl>
引入 zipcodeR 所带的 zip_code_db 数据库,我们可以很方便的获得 zipcode 这一级的人口统计数据,聚合到 county 之后,只保留我们需要的,如下:
# A tibble: 6 x 2
county_id usage
<chr> <dbl>
1 01001 0.377
2 01003 0.439
3 01005 0.292
4 01007 0.120
5 01009 0.197
6 01011 0.162
最后通过地图绘制库,分别绘制出来即可,这里两年两张图,usmap、urbnmapr 一人负责一张,简单对比一下。
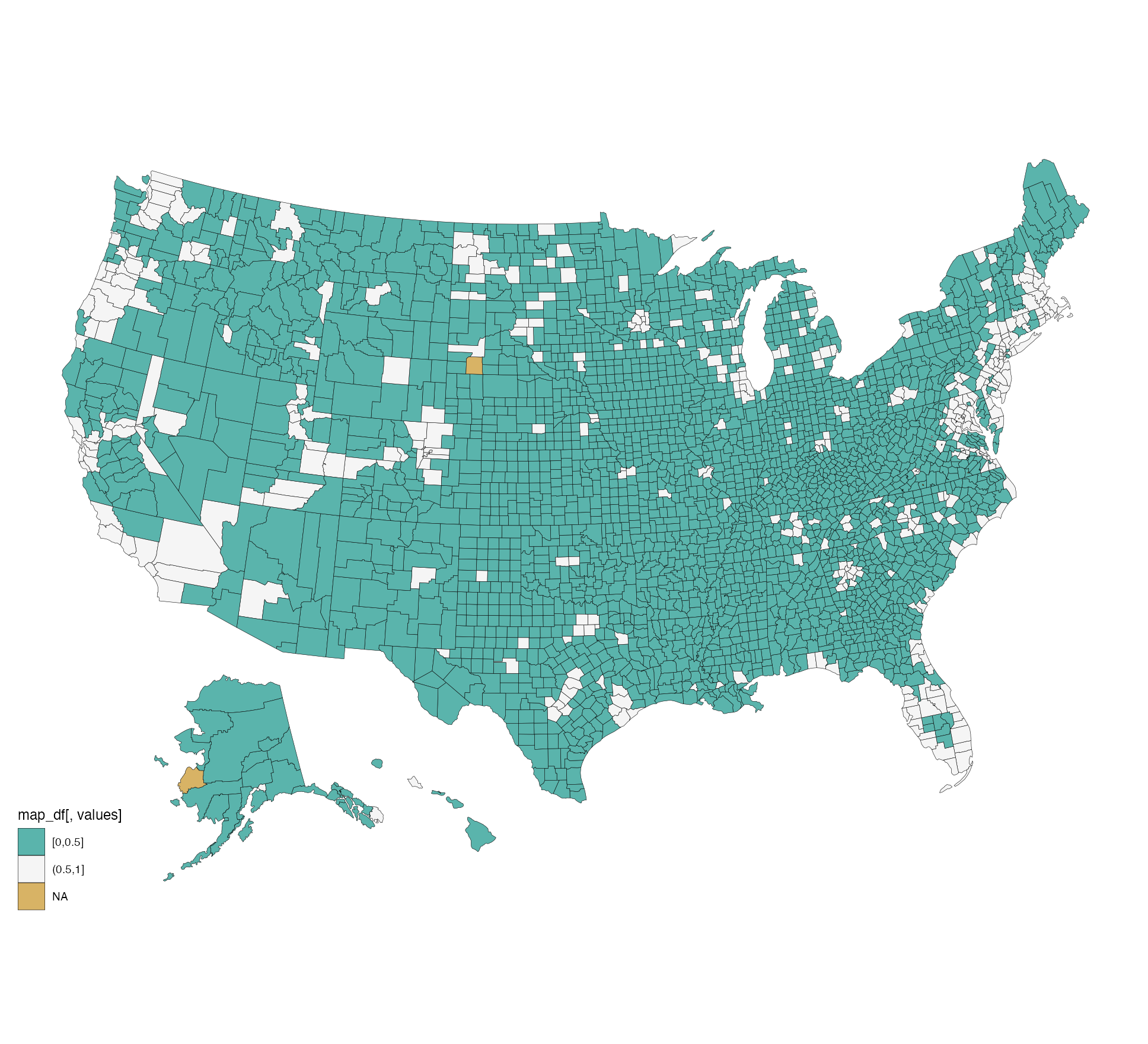
首先,对于 usmap + 2019,只需要指定绘制精度级别、数据及列与 usmap 的映射关系即可,其他设定照着 ggplot2 就行了。为了清晰起见,我在这里将人口比例以 50% 为切线,做了一个二分,颜色突出的,是低于 50% 的县。
plot_usmap("counties", data = bu19 |>
rename(fips = county_id) |>
mutate(tier = cut(broadband_usage,
breaks = c(0, 0.5, 1.0),
include.lowest = TRUE,
right = TRUE)),
values = "tier",
size = 0.1) +
scale_fill_manual(values = c("#5ab4ac", "#f5f5f5"),
na.value = "#d8b365")
然后是 urbnmapr + 2020,过程类似:先指定精度,给你 sf 的选项,需要阿拉斯加等区域,打开它就行(这要在我朝,搞不好就是政治问题 😂️);关联数据,同样二分;后边就是接驳 ggplot2 接口,配置都一样。
get_urbn_map("counties", sf = TRUE) |>
left_join(bu20, by = c("county_fips" = "county_id")) |>
mutate(tier = cut(usage,
breaks = c(0, 0.5, 1.0),
include.lowest = TRUE,
right = TRUE)) |>
ggplot() +
geom_sf(aes(fill = tier), size = 0.1) +
coord_sf(datum = NA) +
scale_fill_manual(values = c("#5ab4ac", "#f5f5f5"),
na.value = "#d8b365") +
theme_void() +
theme(legend.position = "bottom")
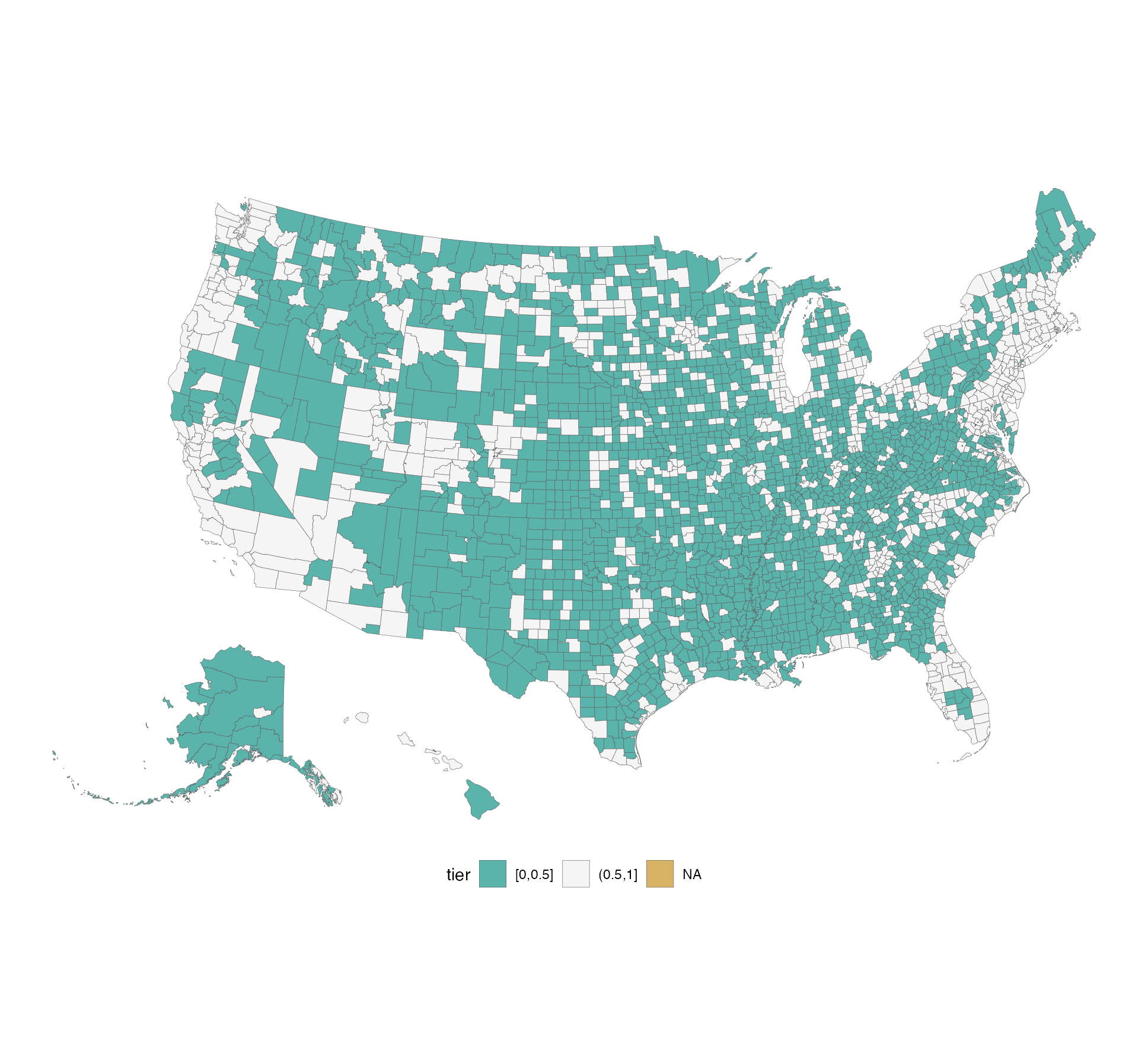
二者,没啥大差别。小结起来:一,可能由于行政变更,2019 个别县映射不到新地图数据上;二,上述配置之下,urbnmapr 的地图初始粒度更细(海岸线、岛屿等);没具体统计,光看图,星星点点,较之 2019 年,一年下来,过 50% 人口的 25 Mbps 宽带覆盖率,是有明显改观的。
最后,要做颜色搭配的话,可以用这个网站,直观、易用:https://colorbrewer2.org/