测量网页的加载时间
一个做官网维护的朋友让我帮忙看一个页面的加载性能,好家伙,看 HTTP 请求,还加载了 8MB+ 的商业字体,这可罕见呐,用在哪了呢,页面全是图,没几个字呀?一查 CSS 调用,原来是 25 个隐藏起来的汉字,鼠标悬停,如果碰巧停对了位置,就能看到效果,与平常的衬线字体区隔度也不大,就是个某某中宋,也不知道买媒体发布授权了没有,😹。今天不讨论人类的多样性,也不笼统妄评性能,只关注一个关于加载时间的 Web API:PerformanceTiming 或是 PerformanceNavigationTiming。
什么是页面加载时间

简单阐述的话,页面加载时间就是浏览器下载、呈现整个页面内容所花的时间,一般说花了多少多少秒。如上图,从发起请求,到页面呈现,大致可以划分为两块,一是网络耗时,包括连接、下载等;一是浏览器耗时,包括解析、渲染等。
但是,落到衡量实现层面,显然不能这么笼统这么对付了,拿到 Google Analytics 的 Page Load Time,我们总得说得出:数据怎么来的,意味着啥,什么情况下可用,够不够说服力等等,不然不说数据驱动业务,它连我们自己都驱不动。
怎么获得加载时间:Navigation Timing API
虽然用户等待时间是衡量 Web 应用质量的重要指标之一,但是自 Web 诞生的很长一段时间以来,并没有一个统一的标准来规范这件事,直到 2001 年 3 月第三届 USENIX 互联网技术与系统研讨会上,两位 IBM 的研究员 Ramakrishnan Rajamony 和 Mootaz Elnozahy 在一篇名为《Measuring Client-Perceived Response Times on the WWW》的论文中提出了一个基于 JavaScript 和浏览器文档标准事件的客户端度量实现,忠实记录真实用户所感知的延时。
标准化组织也没闲着,自 2010 年 8 月起,Web 性能工作组就已经为 Web 引入了大量时间信息记录,可以通过 window 对象的 performance 属性去获取,之后逐渐形成整个 Navigation Timing 接口,包含三个部分:PerformanceTiming 接口(定义了从 navigationStart 至 loadEventEnd 的 21 个只读属性),PerformanceNavigation 接口(定义了当前文档的导航信息,比如是重载还是向前向后等),window.performance 属性(前两者的数据访问接口,通过 performance.timing 获取时间信息,通过 performance.navigation 获取导航信息)。
下图就是上文提及的第一版的 Navigation Timing 的处理模型。自当前浏览器窗口提示卸载旧页面开始,到被访问的新页面装载完成结束,整个过程一共被切分为 9 个小块:提示卸载旧文档、重定向/卸载、应用缓存、DNS 解析、TCP 握手、HTTP 请求处理、HTTP 响应处理、DOM 处理、文档装载完成。每个小块的首尾、中间做事件分界,取 Unix 时间戳,两两搭配计算时间差,获得中间过程的所耗时间,精确到 milliseconds。
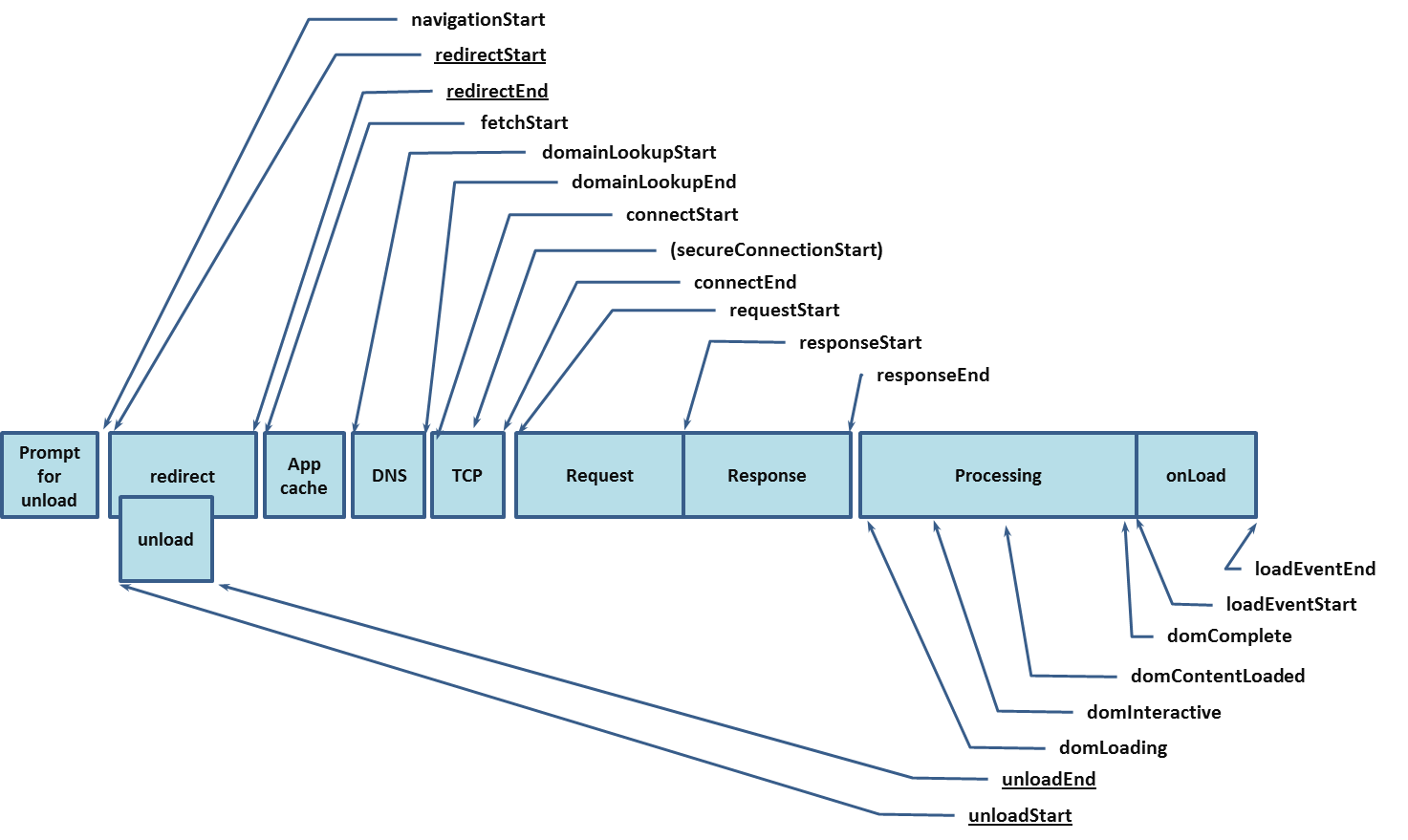
上图是 Level 1 的规范,2012 年底进入候选建议阶段,至今仍在日常使用中,但是在 W3C 的议程上,它已经功成身退,让位给了精度更高,功能更强大,层次更分明的 Level 2(处理模型如下图)。比如被单独拎出来的 Resource Timing,使得我们可以去衡量具体的资源耗时。

浏览器是怎么工作的
想全面了解这个问题,一定要花时间读一下《浏览器是如何工作的》这篇文章,作者 Tali Garsiel,时间 2011 年。有两个必读理由,一是她的研究做的非常全面,质量非常高,有 Paul Irish 等人的背书;二是这种研究做的人少,虽然时隔多年,但也没太多其他的等量内容可以看。文章有中文翻译,但建议对比着看,很多概念还是要看原词原文才更有画面,比如 Parser、Rendering 等等。
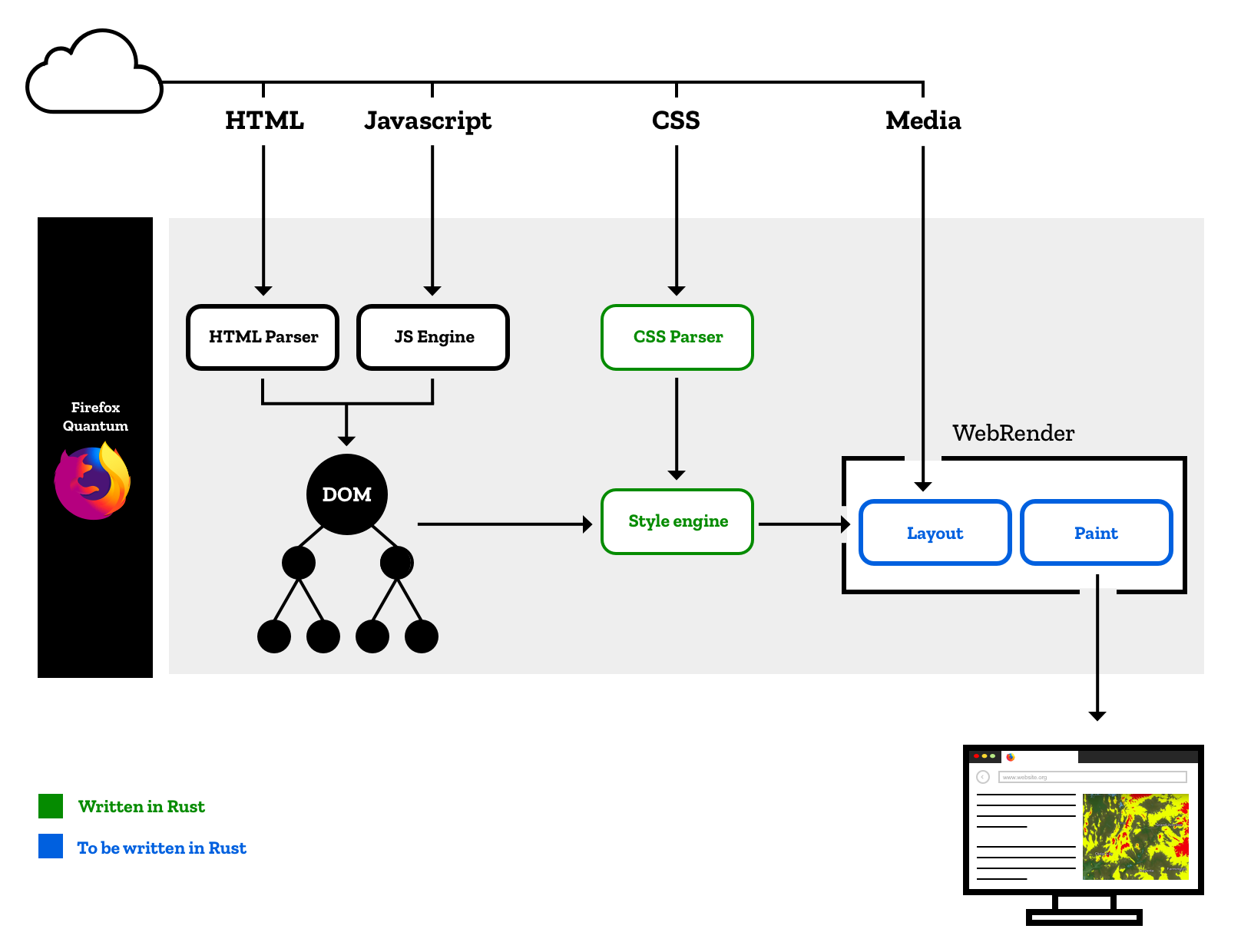
上图是 Firefox Quantum 的 Servo 引擎示意图,它为 Firefox 提供了两个组件,一是并行 CSS 样式处理引擎 Stylo,它已经在服役;一是绘制引擎(Paint Engine),名为 WebRender,它还在使用 Rust 编写中。从上图我们可以看到浏览器需要处理很多东西,比如 HTML、JavaScript、CSS,以及其他资源比如图片、视频等等,然后再把处理结果绘制到屏幕上。大致的总体结构如下图,包含七大块,自上而下分别是:用户界面、浏览器引擎、渲染引擎、网络、JS 解释器、用户界面后端、数据存储。

其中渲染引擎(或呈现引擎,Rendering Engine)是干活的主力。为了用户体验,它并不会等到所有 HTML 都解析完了才显示内容,跟网络数据的分包一样,它也是一个持续渐进的过程,它先是从网络层获取到一小块已经下载的内容,然后经过如下图的处理,然后再重复这个过程:

先看这个循环的一块切片:第一个动作是解析 HTML,即把 HTML 里面的一个一个元素转化为 DOM 节点,一个一个的节点再构建成 DOM 树,或者叫做内容树(Content Tree);引擎同时也会解析 CSS 样式信息,CSS 对象对应的是 CSSOM,样式加上前面的内容,组成渲染树(Render Tree),它包含的是一些带颜色、尺寸等视觉属性的方块,这些方块的顺序就是它们在屏幕上的顺序;渲染树完成之后就会经过一个布局过程,也就是在屏幕上给这些排好了序的枝枝丫丫指定一个具体的位置坐标;再往下就是绘制(Painting)了,也就是遍历整个渲染树,通过界面后端(UI Backend)把每个方框按顺序按位置画到屏幕上。

解析 HTML、CSS,获得 DOM Tree & 样式信息,二者组合成 Render Tree,经由布局,绘制,最终显示到屏幕上。总体的呈现过程如此,浏览器不一致,细节略有不同。


理解 Navigation Timing API
现在,再回过头来看 Navigation Timing API 的处理模型,以 Level 2 为例,我们从头至尾来尝试梳理一下这中间的过程和概念:
整个过程中的什么时点触发什么事件(event)都得到标准规范,并由各浏览器做具体的实现,用户或开发者只需通过约定的方法去访问对应的接口即可获得高精度的时间戳数据。
第一段是前序窗口的处理,如果有就卸载(unload)并记录时间,没有就是 0(比如新窗口打开)。第二段,一开始如果没有重定向,那么这一项的开始和结束时间戳都为 0,然后进入正式的内容获取过程(Fetch Process)。如果没有可用的本地缓存,则联网获取,先是域名解析(DNS),然后是 TCP 握手,然后是发起请求(Rquest)、获得回应(Response),至此资源获取时间结束(Resource Timing)。对于 HTML 页面本身,则还有 DOM 处理以及就绪之后的 load 事件的触发。
对于我个人来讲,Resource Timing 这一侧容易区隔,容易混淆的是 DOM 这一侧。如何理解 DOM 处理以及 loadEvent 这一段过程,Google 开发者文档中有一篇名为《Measuring the CRP》的文章阐述的简单明了。我们结合上文的浏览器工作原理以及 W3C 的 HTML 5 规范,做一个简单整理。
domLoading:浏览器即将开始解析收到的第一小块 HTML 字节domInteractive:全部 HTML 解析完成,DOM 树就绪domContentLoaded:DOM & CSSOM 就绪,可以构建渲染树domComplete:页面全部内容完成,包括各种图片等等(进度条跑完了)loadEvent:发出结束信号
许多 JavaScript 会选择在 domContentLoaded 这个阶段执行,因此,设计者特意设计捕捉了 eventStart 与 eventEnd 两个时戳来帮助我们跟踪这些 JavaScript 的执行时间。如果期间没有 JavaScript 拦截 HTML 解析器,domContentLoaded 会紧跟 domLoading 触发。
动手实践
这篇文章引用了许多站外图片,本地测试时,W3C 那两张图尤其的慢,所以估计页面加载时间很长,正好拿来做个实验,看看每张图片从开始到下载完成所耗时间。注意:计算 Resource Timing 用到了 Level 2 的接口,可能很多浏览器还不支持,请使用最新版的 Firefox 或 Chrome。页面加载进度条走完之后,点击以下按钮,即可看到本页的加载时间都耗在哪个资源身上了。
点此查看各资源加载耗时
LazyLoading 往往是解决加载速度慢的一个时兴手段之一,它把一些首屏显示的非必要资源往后挪了,所以想要了解后续资源的加载时间消耗,或者说速度,就要用到 Resource Timing API 了。本页图片加载耗时看完,再来理解一下 Google Analytics 的页面加载时间的维度。
Google Analytics 提供的 Site Speed 报告也是基于 Navigation Timing API 这个接口实现的(注意区别于 GA 的 User Timing),只是 GA 系统界面和它的开发文档上的用词并不是特别统一,我们可能拿不准哪个是哪个,我们可以自己构造一个 GA timing hit,然后根据参数缩写、参数值以及 performance.timing 内个属性结果的换算值,去反推 GA 的维度名称对应关系和计算方法。最后,还可以通过搜索 analytics.js 源码来核对。
Ec = function(a) {
var b = O.performance || O.webkitPerformance;
b = b && b.timing;
if (!b) return !1;
var c = b.navigationStart;
if (0 == c) return !1;
a[Eb] = b.loadEventStart - c;
a[Gb] = b.domainLookupEnd - b.domainLookupStart;
a[Jb] = b.connectEnd - b.connectStart;
a[Ib] = b.responseStart - b.requestStart;
a[Fb] = b.responseEnd - b.responseStart;
a[Hb] = b.fetchStart - c;
a[Kb] = b.domInteractive - c;
a[Lb] = b.domContentLoadedEventStart - c;
a[Ve] = N.L - c;
a[We] = N.ya - c;
O.google_tag_manager && O.google_tag_manager._li && (b = O.google_tag_manager._li,
a[Xe] = b.cst,
a[Ye] = b.cbt);
return !0
}
维度、Hit 参数缩写、以及计算方法,我的推测如下表,跟 analytics.js 的源码核对之后,错了一个 rrt(Redirection Time)。我以为是 .redirectEnd - .redirectStart,GA 是 b.fetchStart - b.navigationStart。如果没有重定向,redirectStart 和 redirectEnd 的值都会是 0,用 redirectEnd 之后的 fetchStart 减去 redirectStart 之前的 navigationStart 一般会有一点点时间差,但不一定是 redirect 所致,见仁见智吧。
| GA 维度(Hit 参数) | Navigation Timing API | 说明 |
|---|---|---|
| Page Load Time (plt) | .loadEventStart - .navigationStart | 网页加载总耗时 |
| Redirection Time (rrt) | .fetchStart - .navigationStart | 重定向耗时 |
| Domain Lookup Time (dns) | .domainLookupEnd - .domainLookupStart | 域名解析耗时 |
| Server Connection Time (tcp) | .connectEnd - .connectStart | 建立连接耗时 |
| Server Response Time (srt) | .responseStart - .requestStart | 服务器响应耗时 |
| Page Download Time (pdt) | .responseEnd - .responseStart | 页面 HTML 下载耗时 |
| Document Interactive Time (dit) | .domInteractive - .navigationStart | DOM 就绪耗时 |
| Document Content Loaded Time (clt) | .domContentLoadedEventEnd - .navigationStart | DOM/CSSOM/JS 完成耗时 |
这个图结合这个表,这样一看,Site Speed 报告就相对容易理解和使用了。很多人喜欢说「数据不会说谎」,但「数据不会说谎,但说谎的人会算计」(查尔斯·格罗夫纳)。只有理解了它怎么来的,又是怎么加工的,才能借助它还原真相、验证猜想。
与页面停留时间的关系
Google Analytics 的每个 Hit 请求带时间戳,它的页面停留时间(Time on Page)就是通过这个时间戳来计算的。比如第一个页面的停留时间就等于第二个页面的 Hit 时间戳减去第一个页面 Hit 的时间戳。但是这个有一个问题,即如果没有第二个 Hit,第一个页面的停留时间是统计不到的。
Anyway,页面停留时间与页面加载时间的关系,取决于 GA 的埋点方式,以异步代码为例,在页面的逐步加载过程中,GA 代码越靠前,页面资源越复杂可能影响越大,因为很可能页面还没有呈现在用户眼前,GA Pageview Hit 已经早早触发,这样,有一段加载时间被计入进了停留时间,如果时间是敏感维度,这个问题还是需要考虑的。