Pandas 加 netaddr 获取海外 IP 数据
最近折腾分流,想把 IP 做国内外区分,国内直连,国外代理,期望内外网都得到加速。之前都是用他人现成的清单,遇到点疑问,于是自己琢磨一下。由于我处运营商暂不支持 IPv6,以下仅涉及 IPv4。
IP 的表示
IPv4 由 4 段十进制数字组成,每段从 0 至 255,如下图,换算成二进制,即 4 个 8 位,一共 32 位(bits),1 bit 有 0 和 1 两个值,因此 IPv4 总数即为 2^32 个。这只是 IPv4,还没算地球上每粒沙子都能分到一个的 IPv6。IP 形式复杂,总量又大,涉及面广,如何管理和分派一直是个大问题,方案也一直在演进,CIDR 是现今使用的 IP 分配、归类方法。

CIDR,无类别域间路由。所谓无类别,是相对于早期的分类网络而言的,当时将 IP 地址分做两个部分,网络和主机,并据公、私、保留等用途拆做 5 个大类,现在还经常听得到,即 A、B、C、D、E 类等等。老分类法的问题在于:它的区块,小的太小,大的过大,比如,最小块才 256(24位前缀,8位主机地址,2^8 = 256)个主机地址,企业、组织稍大点就不够用;大块则高达 65536(16位前缀,16位主机,2^16 = 65536)个地址,用不完又太浪费。正由于它的分配效率不高,上世纪九十年代初,CIDR 被提了出来,以应对分类网络(Classful Addressing)的各项问题。
CIDR 是一个按位的、基于前缀的,用于解释IP地址的标准。感觉有点像把之前大落差的断崖式分类变成了细密平滑的剥笋式。分配时,按需分块,可大可小,高效灵活。一个 CIDR 块由两个部分构成:起始 IP + 前缀长度,记作 a.b.c.d/N。一个块包含多少个以及具体哪些 IP 地址,都可以由此推算出来。
比如 172.16.254.1/27,它表示这个 CIDR 块的起于 172.16.254.1,前缀长度为 27,什么意思呢,参考下表,先把 172.16.254.1 转换成二进制数,这里所说的前缀,就是这个 32 位二进制数的前 27 位,即 10101100 . 00010000 . 11111110 . 000。由于一个 IPv4 地址总长 32 位,前边固定了 27 位,那么这个区块还能变动出来 IP 的位置即为 32 - 27 = 5(bits),所以 172.16.254.1/27 涵盖的 IP 就是 172.16.254.1 至 172.16.254.31 的一共 2^5 = 32 个地址。
10101100.00010000.11111110.00000001 #172.16.254.1
xxxxxxxx.xxxxxxxx.xxxxxxxx.xx|
10101100.00010000.11111110.00011111 #172.16.254.31
xxxxxxxx.xxxxxxxx.xxxxxxxx.xx|
10101100.00010000.11111110.00100000 #172.16.254.32
xxxxxxxx.xxxxxxxx.xxxxxxxx.xx!
分配
分配是自上而下的,IANA 先向全球几大 RIR 派发大块的 CIDR 地址,RIR 再根据地方的申请,大块拆小块,分发给区域内的各大 ISP,然后再继续往下。
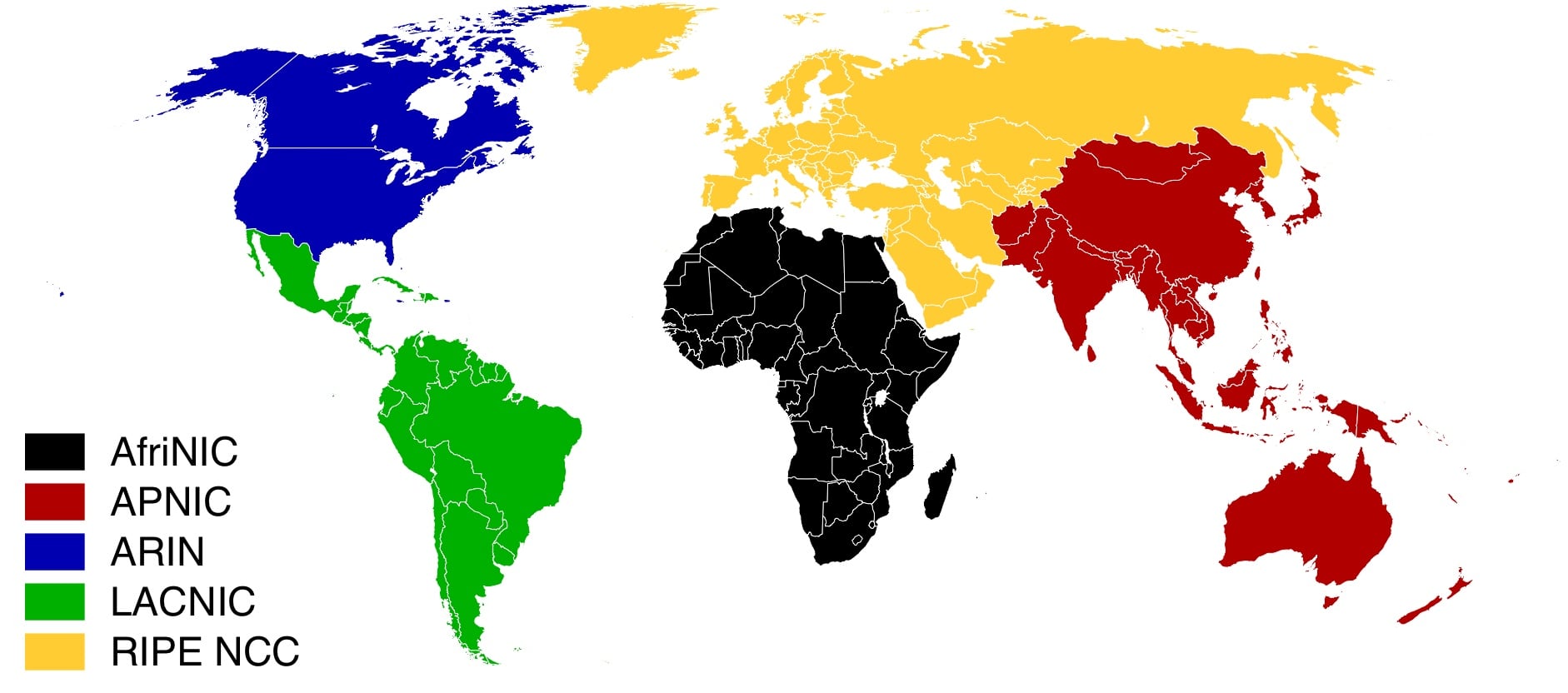
区分国内外 IP,是 RIR 层面的事情,所以去 APNIC 亚太网络信息中心下载最新的分发数据,然后提取其中属于中国的部分即可获得 CN 子集,然后 CN 交保留 IP 段,去取 IPv4 全集的补集,就是海外 IP 段了。
动手
如上管窥,虽然已经知晓了规则,又有了数据,但 IP 情况复杂,看起来一个样,做起来一个样,实际花了不少时间。最终选择的工具集如下:
- Python 3
- Pandas,Numpy,netaddr/IPSet
首先是 Python 3 + Pandas,这其实是平常做分析的工具,属于习惯性选择,而且 APNIC 提供的其实是一个 CSV,非常适合用 Pandas 来处理,其字段介绍看:这里;另外,保留 IP 取自维基百科,是一个网页 <table>,Pandas 爬取、解析都方便;最后,使用 netaddr 的 IPSet 方法来管理和运算 CIDR 集合,专事专办,它的范例则在:这里。
抛开严肃编程的异常管理等方面,业余选手的产出如下图,理顺了倒也不算复杂,这其中,Pandas 解决了不少文件 IO 和数据处理的问题,IPSet 负责了 CIDR 的数据结构和运算。费解之处,可能是 Pandas 那一段,没办法,事情总是这样,高级 API 虽易用,却由于隐藏了复杂推导,解释起来反而麻烦。
平常的操作台是 Jupter Notebook,一个 Cell 就是一张稿纸,写代码做测试是很随意的,在这里,为了逻辑清晰起见,现学现卖,用了 Pandas 较为现代的方法链(Method Chaining)功能,而为了这个实现这个链,又把绕口罕用的 loc、assign 以及 pipe 等功能都拼凑到一起,算是生搬硬套。

总之,个人偏好产物,不怎么好移植,也不值得非 Pandas 玩家借鉴。另外,如果遇到 Wikipedia 被墙,出现 connection refused 之类的报错时,请考虑引入 requests,添加 proxies 属性。
import numpy as np
import pandas as pd
from netaddr import IPSet
apnic_url = 'http://ftp.apnic.net/apnic/stats/apnic/delegated-apnic-latest'
reserved_url = 'https://en.wikipedia.org/wiki/Reserved_IP_addresses'
ipv4 = IPSet(['0.0.0.0/0'])
reserved = IPSet(pd.read_html(reserved_url)[0]['Address block'])
cnip = (pd.read_csv(apnic_url, skiprows=31, header=None, sep='|')
.loc[lambda x: (x[1] == 'CN') & (x[2] == 'ipv4')]
.assign(suffix = lambda x: np.log2(x[4]).astype(int))
.assign(cidr = lambda x: x[3] + '/' + x['suffix'].astype(str))
.loc[:, 'cidr']
.pipe(IPSet))
overseas = ipv4 ^ (cnip | reserved)
with open('overseas_ip.txt', 'w') as f:
for ip in overseas.iter_cidrs():
f.write(f'{ip}\n')