Big Mac Index
昨天晚上看 WWDC 开场演讲,满心以为要发布点能干重活的 Mac,结果一粒沙子都没看见,导致今天上班都有点恍惚。提到 Mac,R 社区 rfordatascience/tidytuesday 2020 年第 52 周的数据 The Big Mac index 正好也是讲 Mac 的,关公战秦琼,拉出来看一看,玩一玩。
library(tidyverse)
big_mac <- read_csv("https://github.com/TheEconomist/big-mac-data/releases/download/2021-01/big-mac-full-index.csv") |>
janitor::clean_names()
# A tibble: 1,386 x 19
date iso_a3 currency_code name local_price dollar_ex
<date> <chr> <chr> <chr> <dbl> <dbl>
1 2000-04-01 ARG ARS Argentina 2.5 1
2 2000-04-01 AUS AUD Australia 2.59 1.68
3 2000-04-01 BRA BRL Brazil 2.95 1.79
4 2000-04-01 CAN CAD Canada 2.85 1.47
5 2000-04-01 CHE CHF Switzerla… 5.9 1.7
6 2000-04-01 CHL CLP Chile 1260 514
7 2000-04-01 CHN CNY China 9.9 8.28
8 2000-04-01 CZE CZK Czech Rep… 54.4 39.1
9 2000-04-01 DNK DKK Denmark 24.8 8.04
10 2000-04-01 EUZ EUR Euro area 2.56 1.08
# … with 1,376 more rows, and 13 more variables:
# dollar_price <dbl>, usd_raw <dbl>, eur_raw <dbl>,
# gbp_raw <dbl>, jpy_raw <dbl>, cny_raw <dbl>, gdp_dollar <dbl>,
# adj_price <dbl>, usd_adjusted <dbl>, eur_adjusted <dbl>,
# gbp_adjusted <dbl>, jpy_adjusted <dbl>, cny_adjusted <dbl>
1,386 x 19 的小数据集,19 列看起来似乎很多,看列名,其实除去日期、国家代码、货币代码、国名、汇率之后,剩下的都是 Big Mac 指数在 USD、EUR、CNY、JPY 等常见货币之间的换算关系,可以理解为一回事。


那么,何为 Big Mac Index?首先,这里的 Mac 不是💻电脑,而是🍔巨无霸汉堡;其次,要理解这个巨无霸指数是什么意思,得先了解一个概念——PPP(purchasing power parity),它是这个指数成立的前提。那么,PPP 又是什么呢?它译作「购买力平价」,大意是这样的:世界各国都有自己的货币,自成体系,不好直接比较说一块人民币换一块美刀是高了还是低了。为了方便比较,它先做了一个假设,假设一些全球流通的商品,价值在哪里都是一样的,那么,只要比较这些商品在各地的价格,再结合当时的实际汇率,我们就能顺理成章的推断当地货币是被高估了还是被低估了。
那选什么商品好呢,最起码,它要既方便简单操作,且又全球流通。提出这个指数的《经济学人》说,当然是大汉堡了,并且自苹果发布 Mac(Macintosh)的 1984 年之后的两年起,《经济学人》开始坚持每年出版一次汉堡指数,帮助大家据此理论,简单评估汇率的差异。
那么,道理我都懂,汉堡为什么那么大,到底什么是巨无霸指数呐?再举个实例,假如同样一个麦当劳大汉堡,在美国卖 6 块钱一个,在中国卖 24 块钱一个,那么,两地汉堡指数是 6:24,即 1:4。那么,现在美元与人民币的汇率是多少呢,是 1:6.4,根据 PPP 理论,与实际汇率相比,通过计算 (1/6.4)/(1/4)-1 = -38%,于是我们说:跟实际汇率相比,人民币相对于美元,被低估了 38%。啥意思?人民币应该据此升值到四块兑一块美金吗?哦,$699 的 RTX 3080 只需 ¥3,355 🎉🎉🎉(大方点算你 20% 增值税)。

话虽如此,但是在实际生活当中,决定一件商品价格的因素可能有很多,比如开店的房租、人工、税收、消防等成本,再比如居民的收入水平等等,可能为了让这个指数看起来不那么粗暴,经济学人又指标数据分作了两个部分,一半是上述逻辑所讲的直接换算,一半则是后边的几列列名带 adj/adjusted 的数值,它们是融合了人均 GDP 之后的调整结果。
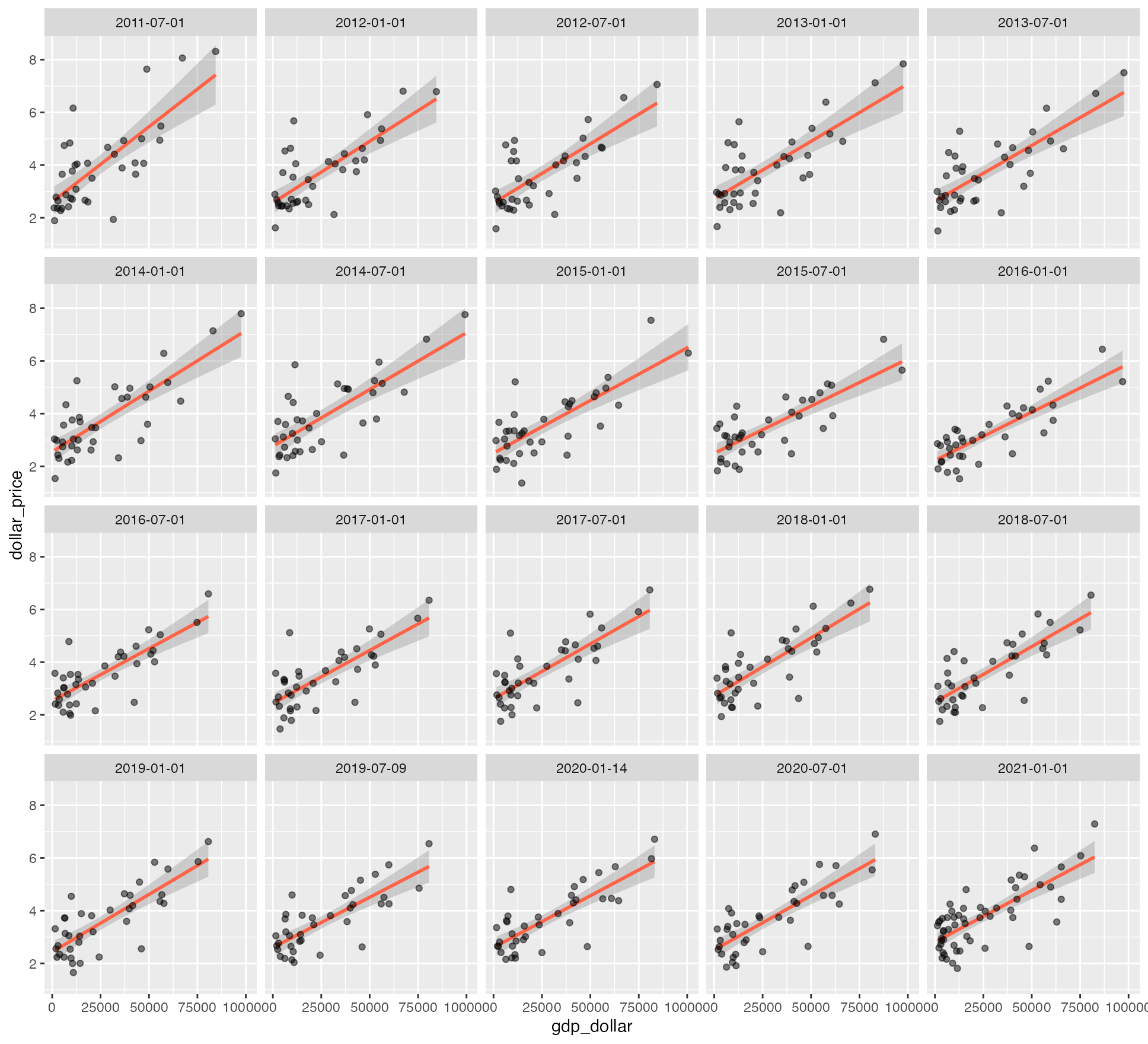
怎么个调整法呢,总体预期是:穷国便宜,富国更贵。上图也可以印证着一预期,具体计算详情可以参考原 GitHub 仓库的 ipynb,引文的最后一个链接可直达。我们可以根据其中一个代码片段来推测,摘录如下:
big_mac_gdp_data[, adj_price := lm(dollar_price ~ GDP_dollar) %>% predict, by = date]
这是一段融合了 data.table + tidyverse + base R 三种风格的 R 代码,DT[i, j, by] 这个外框是 data.table,lm(dollar_price ~ GDP_dollar) %>% predict 这里是 tidyverse + base R。也就是说,以 date 为分组,获得 y = ax + b 的线性关系。这里的 y 是当个 date 窗口内的汉堡原价 dollar_price,x 为人均 GDP GDP_dollar,货币单位,顾名思义,都是换算过的美金。由此,一组 date 决定一条线,线定下来了,游离于线外的老点在新线上的新位置,自然也就出来了。
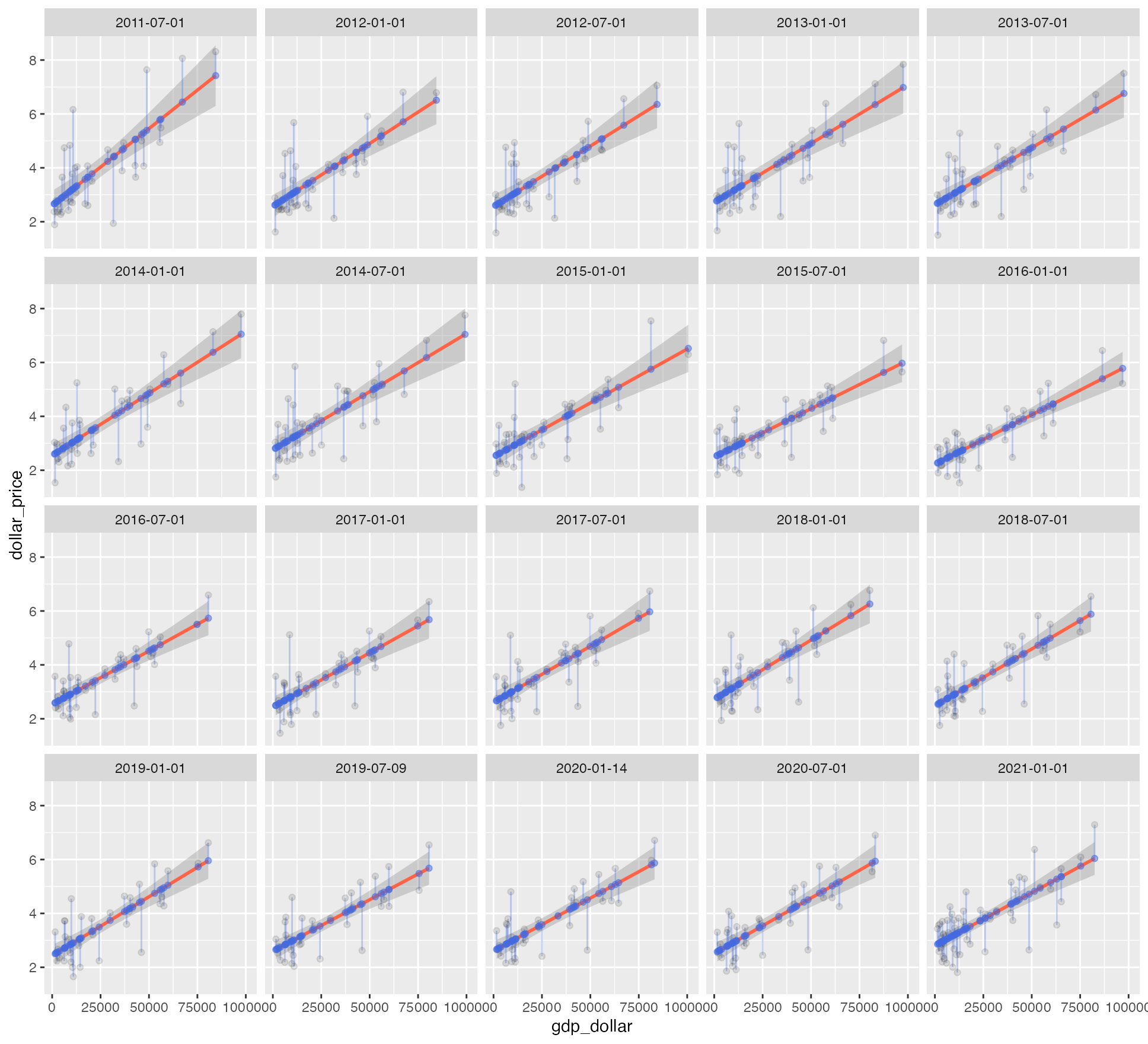
数据不一样了,结论自然也不一样了,新的调整结果下,我们上边的人民币被低估的结论,甚至都反过来了。不如直接看历年来的当地价格变化吧,2000 年以来,难以想象,日本、台湾两地还曾降过价,内地和香港,价格都翻了一倍多,只是一时没有通胀数据,不好结论。
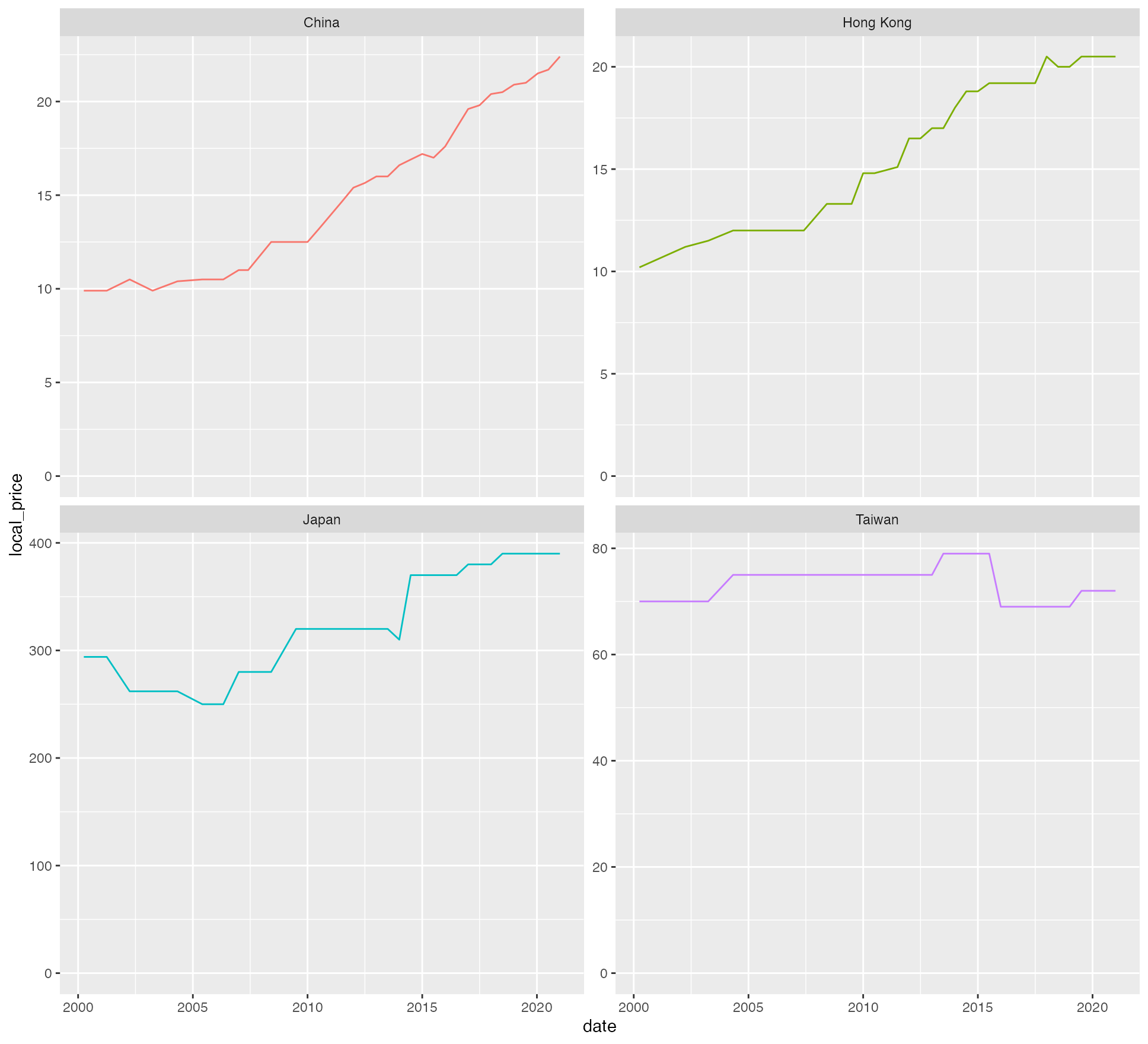
big_mac |>
filter(date >= "2000-01-01",
name %in% c("China", "Hong Kong", "Taiwan", "Japan", "Korean")) |>
ggplot(aes(x = date, y = local_price, color = name)) +
geom_line(show.legend = FALSE) +
facet_wrap(~name, scales = "free_y") +
expand_limits(y = 0)
Source:
- https://github.com/TheEconomist/big-mac-data
- https://github.com/rfordatascience/tidytuesday/tree/master/data/2020/2020-12-22
- https://www.economist.com/big-mac-index
- https://en.wikipedia.org/wiki/Big_Mac_Index
- https://github.com/theeconomist/big-mac-data/blob/master/Big%20Mac%20data%20generator.ipynb